深耕網(wǎng)絡(luò)設(shè)備領(lǐng)域,攜手思科、華為、飛魚(yú)星,共創(chuàng)高效互聯(lián)未來(lái)

在信息化浪潮席卷全球的今天,穩(wěn)定、高效、安全的網(wǎng)絡(luò)環(huán)境是企業(yè)運(yùn)營(yíng)與發(fā)展的基石。我們公司長(zhǎng)期致力于為企業(yè)客戶(hù)提供全面、專(zhuān)業(yè)的網(wǎng)絡(luò)設(shè)備解決方案,憑借深厚的技術(shù)積累與行業(yè)經(jīng)驗(yàn),已成為思科(Cisco)、華為(Huawei)、飛魚(yú)星等國(guó)際及國(guó)內(nèi)頂尖網(wǎng)絡(luò)設(shè)備品牌的核心合作伙伴,在業(yè)界贏(yíng)得了廣泛的信賴(lài)與贊譽(yù)。
一、 強(qiáng)大品牌矩陣,滿(mǎn)足多樣化需求
我們深知,不同規(guī)模、不同行業(yè)、不同應(yīng)用場(chǎng)景的企業(yè)對(duì)網(wǎng)絡(luò)的需求千差萬(wàn)別。為此,我們精心構(gòu)建了多元化的品牌產(chǎn)品線(xiàn):
- 思科(Cisco): 作為全球網(wǎng)絡(luò)技術(shù)的領(lǐng)導(dǎo)者,思科設(shè)備以其卓越的性能、極高的可靠性和無(wú)與倫比的安全性著稱(chēng)。我們?yōu)榭蛻?hù)提供從核心交換機(jī)、路由器到無(wú)線(xiàn)接入點(diǎn)、安全防火墻在內(nèi)的全系列思科產(chǎn)品,是構(gòu)建大型企業(yè)網(wǎng)絡(luò)、數(shù)據(jù)中心及復(fù)雜廣域網(wǎng)的首選。
- 華為(Huawei): 華為是全球領(lǐng)先的ICT(信息與通信)解決方案供應(yīng)商。其網(wǎng)絡(luò)設(shè)備以技術(shù)創(chuàng)新、高性?xún)r(jià)比和出色的本土化服務(wù)見(jiàn)長(zhǎng)。我們提供的華為企業(yè)網(wǎng)絡(luò)產(chǎn)品,覆蓋了園區(qū)網(wǎng)絡(luò)、數(shù)據(jù)中心網(wǎng)絡(luò)、廣域網(wǎng)絡(luò)及網(wǎng)絡(luò)安全等領(lǐng)域,尤其適合追求前沿技術(shù)、注重長(zhǎng)期投資回報(bào)的成長(zhǎng)型企業(yè)及政府機(jī)構(gòu)。
- 飛魚(yú)星: 作為國(guó)內(nèi)知名的商用網(wǎng)絡(luò)品牌,飛魚(yú)星專(zhuān)注于為中小企業(yè)、酒店、校園、連鎖門(mén)店等提供智能、易管理、高性?xún)r(jià)比的網(wǎng)絡(luò)解決方案。其產(chǎn)品在行為管理、流控優(yōu)化、多WAN接入等方面特色鮮明,是我們服務(wù)廣大中小微企業(yè)客戶(hù)的重要利器。
通過(guò)這三駕馬車(chē)的組合,我們能夠?yàn)榭蛻?hù)精準(zhǔn)匹配從高端到入門(mén)、從國(guó)際標(biāo)準(zhǔn)到本土優(yōu)化的全方位產(chǎn)品選擇。
二、 超越銷(xiāo)售的專(zhuān)業(yè)價(jià)值
我們的服務(wù)遠(yuǎn)不止于設(shè)備銷(xiāo)售。我們定位為“企業(yè)網(wǎng)絡(luò)賦能伙伴”,提供的是一站式、全生命周期的價(jià)值服務(wù):
- 專(zhuān)業(yè)咨詢(xún)與方案設(shè)計(jì): 我們的技術(shù)團(tuán)隊(duì)會(huì)深入理解客戶(hù)的業(yè)務(wù)現(xiàn)狀與未來(lái)規(guī)劃,進(jìn)行細(xì)致的需求分析,量身設(shè)計(jì)最優(yōu)化、最具前瞻性的網(wǎng)絡(luò)架構(gòu)方案,確保投資物有所值。
- 原廠(chǎng)正品供應(yīng)與快速交付: 作為授權(quán)合作伙伴,我們保證所有設(shè)備均為原廠(chǎng)正品,渠道正規(guī),享受完整的原廠(chǎng)質(zhì)保與售后服務(wù)。我們建立了高效的供應(yīng)鏈體系,確保客戶(hù)所需設(shè)備能快速、準(zhǔn)確地交付。
- 專(zhuān)業(yè)部署與集成服務(wù): 提供從設(shè)備安裝、調(diào)試、配置到系統(tǒng)集成的全程技術(shù)服務(wù),確保網(wǎng)絡(luò)平穩(wěn)上線(xiàn),與現(xiàn)有業(yè)務(wù)系統(tǒng)無(wú)縫融合。
- 持續(xù)的技術(shù)支持與維護(hù): 我們擁有7x24小時(shí)的響應(yīng)機(jī)制和專(zhuān)業(yè)的技術(shù)支持團(tuán)隊(duì),為客戶(hù)解決日常運(yùn)維中的各類(lèi)問(wèn)題,并提供定期的健康檢查、固件升級(jí)建議等,保障網(wǎng)絡(luò)長(zhǎng)期穩(wěn)定運(yùn)行。
- 培訓(xùn)與知識(shí)傳遞: 可根據(jù)客戶(hù)需要,提供相關(guān)產(chǎn)品的操作與管理培訓(xùn),幫助客戶(hù)的IT團(tuán)隊(duì)提升自身運(yùn)維能力。
三、 廣泛的行業(yè)實(shí)踐
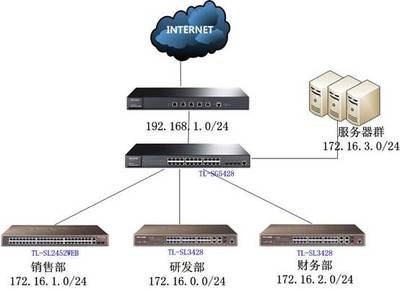
多年來(lái),我們的解決方案已成功應(yīng)用于金融、教育、醫(yī)療、制造、零售、互聯(lián)網(wǎng)、政府等多個(gè)行業(yè),積累了豐富的跨行業(yè)實(shí)施經(jīng)驗(yàn)。無(wú)論是構(gòu)建總部核心網(wǎng)絡(luò),還是部署遍布全國(guó)的分支機(jī)構(gòu)互聯(lián);無(wú)論是打造高密度的無(wú)線(xiàn)辦公環(huán)境,還是建設(shè)承載關(guān)鍵業(yè)務(wù)的數(shù)據(jù)中心,我們都能憑借對(duì)行業(yè)特性的深刻理解,交付令人滿(mǎn)意的成果。
****
網(wǎng)絡(luò)是數(shù)字化轉(zhuǎn)型的動(dòng)脈。選擇我們,不僅是選擇了一系列可靠的網(wǎng)絡(luò)設(shè)備,更是選擇了一位值得信賴(lài)的長(zhǎng)期合作伙伴。我們將繼續(xù)依托思科、華為、飛魚(yú)星的強(qiáng)大技術(shù)后盾,結(jié)合我們自身的專(zhuān)業(yè)服務(wù)能力,助力更多企業(yè)構(gòu)建面向未來(lái)的智能網(wǎng)絡(luò),在數(shù)字時(shí)代暢行無(wú)阻,贏(yíng)取先機(jī)。
如若轉(zhuǎn)載,請(qǐng)注明出處:http://www.ycwuk.cn/product/63.html
更新時(shí)間:2026-06-19 14:41:56